
State-Space Substitution: Creating a VAE-SSM Hybrid Image Generator

Inspiration
Transformer models, the foundation model underpinning for most AI applications today, are very resource intensive, which significantly limits their capabilities. For example, on the fronts of:
Memory — AI video generators have trouble making videos longer than just a few minutes long (released SoTA models from Runway, Pika, and OpenAI don’t generate more than 10 seconds of footage)
Compute — Transformer compute costs scale quadratically, meaning each extra token in a sequence requires more compute than even the token before it; this compounds and makes Transformers very computationally expensive to train and run inference on
Cost — OpenAI is estimated to have spent $11B+ in 2025 on inference alone (and likely a similar amount on training, given previous years’ costs)
Time — Trailblazing Transformer TTS models by startups (ElevenLabs, OpenAI, LMNT) and big tech (Google, Amazon, Microsoft) have trouble shaving latency below 500 milliseconds for time from text input to speech output
In an attempt to solve these bottlenecks with Transformers, a team of researchers from Stanford AI Lab pioneered a new neural network architecture class called state-space models (SSMs). Since graduating from their PhDs under Chris Ré, SSM pioneers Karan Goel and Albert Gu have founded Cartesia, a frontier lab dedicated to building multimodal AI models strictly with SSMs. That being said, the only production models they’ve ever shipped are the Sonic series for speech synthesis—not processing or generating images, text, video, or the other modalities they intend to enable. This makes sense: companies often must stay focused and invest high amounts of resources into nailing singular products before scaling—and they have so far nailed the text-to-speech (TTS) task, becoming a consensus go-to for many top AI companies using speech generation in their pipeline (on par with ElevenLabs). However, given the issues the architecture is intended to address, SSMs offer significant promise for applications in the computer vision domain as well.
SSMs’ unique advantages, including their flexibility in handling sequences at varying scales, offers the potential to dynamically adjust resolutions of outputs during inference—allowing folks to more seamlessly make quality-latency tradeoff decisions [1]. Currently, the most popular techniques for image generation include diffusion models, VAEs, and Transformers.
I furthered this research by switching out one of the convolutional layers from a 3-layer VAE image generator with an SSM layer to see if it is able to successfully assist with the image generation task. Despite not being the absolute best image architecture for image generation, I chose to modify a base VAE model because VAEs are significantly more computationally efficient to train on the hardware resources I have access to (compared to diffusion models). While diffusion models are widely considered state-of-the-art in terms of image generation output quality, they require much more compute and have longer training times, making time-efficient training, prototyping, and experimentation difficult for a weekend project.
Related Research Work
1. Image Generation Techniques:
Generative Adversarial Networks (“GANs”) were one of the first model architectures to deliver high-quality image synthesis results by pitting two neural networks against each other: a generator (which creates the images) and a discriminator (which evaluates authenticity). Goodfellow et al. introduced GANs in 2014 [2], a team from Courant Institute and FAIR released the Wasserstein GAN in 2017 [3], and many teams since have leveraged GANs for the image generation task (e.g., StyleGAN in 2018, BigGAN in 2019).
Variational Autoencoders (“VAEs”), characterized by their ability to encode data into latent spaces and decode it back, were also quite popular in the mid-2010s for the image generation task. Kingma & Welling (2013) proposed that VAEs could be trained end-to-end via gradient descent and introduced VAEs for generative modeling; since then, many have adapted VAEs for image generation tasks. For example, Huang et al. (2018) developed an introspective VAE (“IntroVAE,” as they call it) that can evaluate its own images’ model quality and improve itself without human feedback or a discriminator which yielded comparable results to SoTA GANs at the time. While VAEs are no-longer state-of-the-art, some researchers such as Liu et al. (2025)—authors of “Research on the Application of Variational Autoencoder in Image Generation”—continue to use the technique for image generation.
Diffusion models, the widely popular method used by Stable Diffusion, Midjourney, and DALL-E for AI image synthesis, generate images by first adding random noise to training images and then learning to reverse this process (step-by-step) to reconstruct clean images from the noise [4]. While early diffusion models were very computationally expensive and often had slow inference, Rombach et al.’s 2022 “High-Resolution Image Synthesis with Latent Diffusion Models” applied the diffusion possess in the compressed latent space of a pre-trained autoencoder and yielded better results—with lower training and inference costs but comparable quality [5]. Since then, diffusion models have become widely popular in the computer vision domain.
2. State-Space Models
Entitled “Efficiently Modeling Long Sequences with Structured State Spaces,” Karan and Albert’s massively successful SSM paper introduced S4, a new model architecture designed to efficiently handle very long sequences—the core value proposition of SSMs [1]. The paper proposed a new parameterization of SSMs that made the matrix A diagonalizable with low-rank correction, decreasing the computation to a Cauchy kernel. S4 yielded SoTA results on every task from the Long Range Arena benchmark and demonstrated ~60x faster inference than Transformers for similar image and language modeling tasks.
A follow-up paper by Albert Gu and Tri Dao built upon S4 by introducing input-dependent parameters, allowing the SSM to dynamically control which information to retain or discard at each step—something Transformers don’t do when running inference [6]. Although this hinders the convolutional speed-ups of S4, Mamba introduced a hardware-efficient algorithm for when using recurrents. Perhaps Mamba’s biggest achievement was the fact that inference time and cost scales linearly (compared to Transformers, which scale quadratically) with input sequence length. However, it also gave rise to 5x faster inference and promise for a variety of modalities—including audio, text, and genomics.
3. SSMs in Computer Vision
While SSMs have not been widely adopted in the computer vision domain, there have been some exciting research developments leveraging SSMs for image and video tasks. The Cartesia team’s attempt at this is S4ND, an architecture which replaces the Conv2D and attention layers with S4ND blocks—outperforming the Vision Transformer on ImageNet-1k (by 1.5%) and improving a 3D ConvNeXt in activity classification (by 4%) [7]. While an S4ND repository has been open-sourced by the research team, it is hard to use and Cartesia and lacks comprehensive documentation.
Building on this research, Hong et. al developed an SSM-Transformer hybrid model (5B parameters) capable of generating high-resolution images (2K) and videos (8 seconds at 360p). [8]. Their (under review) paper supported the notion that SSMs combined with other model architecture could yield meaningful results in computer vision. This was an inspiring study as I tried to create a hybrid model myself—albeit with VAEs and SSMs.
Furthermore, written by a Chinese team primarily from University of Chinese Academy of Sciences (UCAS), VMamba (“Visual State Space Model”) adapts Mamba for vision tasks by integrating global receptive fields with linear complexity [9]. They propose a Cross-Scan Module (CSM) to “traverse the spatial domain and convert any non-causal visual images into order patch sequences,” thus improving model quality. VMamba especially showed strong performance as image resolution increases, offering a strong alternative to both CNNs and Vision Transformers (ViTs) for visual representation learning.
However, SSMs are trying to be applied to vision tasks in the real-world as well! A team of Apple scientists wrote a paper on “Human Motion Understanding using State Space Models,” applying SSMs to video-based motion understanding of humans [10]. Compared to Transformers, which struggle with real-time sequential prediction and generalization across frame rates, HumMUSS has lower latency, is more memory efficient, and adaptable to both online and offline tasks—exhibiting the core value propositions of SSMs. The team cites it as both surpassing Transformer models’ approach for similar tasks and for bringing additional benefits (e.g., adaptability to different video frame rates).
Together, these papers carry enough promise that meaningful developments in image generation are possible to inspire an exploration into integrating SSMs into image generation programs.
Methods
1. CelebA Dataset:
I selected the CelebFaces Attributes (CelebA, “celeb_a”) dataset to train on (for both the VAE and VAE-SSM hybrid models) for several reasons. First, it is a large-scale dataset with over 200,000 celebrity face images. Although I didn’t use the granular, high-quality annotations signaling gender, age, hair color, and facial expressions for this experiment, this could have been helpful as an extension should I have allocated more time to train models well-suited for generating images with more granular attributes (e.g., gender, age, etc.). Second, all of the images in CelebA are relatively confined in their nature—all of them are simply faces, well aligned and cropped in the middle of images, with a constant image resolution (178 x 218 pixels). This uniformity across the dataset reduces the visual variability that the model might otherwise struggle with when training on a broader image dataset (e.g., ImageNet, which hosts images with many unrelated and variable categories, like vehicles and dogs), especially when not using the extra annotations. Finally, the extensive use of CelebA in other computer vision research initiatives (including many involving VAEs) helps provide a valuable benchmark [11]. By training on this well-established dataset, it’s easier to compare and contrast the results of the VAE and VAE-SSM hybrid models against those of previous image generators trained on CelebA, assisting with simple evals.
2. VAE Overview:
Variational Autoencoders (VAEs) are generative models that learn to compress data into structured latent space and then decode samples from that space to synthesize new outputs. Like standard autoencoders they have an encoder, a bottleneck, and a decoder, but unlike standard autoencoders (which deterministically map inputs to single latent vectors), VAEs encode latent variables as probability distributions. For each attribute of the training data (input images, in this case), the encoder predicts two different latent vectors: the mean (μ) and the log-variance (log σ2) of the approximate posterior. The VAE learns an approximate posterior over latent variables end-to-end, and its bottleneck is the low-dimensional latent space produced by the encoder. If this latent space is too large (or too weakly regularized), the model can bypass appropriate compression and effectively memorize the training set. At generation time, the decoder produces new samples by drawing a latent vector from the learned latent distribution and mapping it back into image space, yielding outputs that are novel but consistent with training data.
3. CNN-only image generator:
To establish a baseline for image generation, I initially trained a VAE for image generation on CelebA. I trained it with images in the format of 64 x 64 pixels because that is how a successful public GitHub repository did so [12]. My VAE holds both the encoder and decoder as multivariate Gaussian distributions, and I used the code from this repository’s linked pytorch notebook to run the VAE [13]. Both the encoder and the decoder of the model are built from convolutional layers and fully connected blocks. The encoder consists of five 2D convolutional layers, each followed by a ReLU activation function that predicts the parameters of a Gaussian distribution in latent space (The mean of the approximate posterior and the log variance of the distribution). The decoder mirrors the encoder i.e. the layers are in reverse order. I trained for 200,000 steps using a batch size of 32 and evaluated the model every 2,000 steps. There were many dependency, size fighting, and debugging errors I faced as I tried to write a Python script which ran the code to train this VAE for the image generation task and run inference to generate a batch (batch sizes of 32), though I was able to solve them. I ran training for 200,000 steps, which took roughly 4 hours. One challenge I faced was a mysterious crashing of the training process every 5084 steps, but I overcame this by adding checkpointing logic which would reset at the last chunk of 2000 each time the program crashed and restart training from there.
4. VAE-SSM hybrid model:
While traditional VAEs use convolutional networks (and, more recently, Transformers), I used S4D because it can efficiently model long sequences of data—which, in theory, should work great for images. I flattened each image of size 64x64 pixels into a sequential vector of size [4096x1]. The model was trained for 60,000 steps with a batch size of 8 images and evaluated every 2,000 steps. Below is the encoder architecture (mirrored to form the decoder):
1x1 convolution: Projects each pixel’s RGB vector into a higher-dimensional features space so it can be processed by S4D.
Image flattening: Reshapes the 2D image (64 x 64) into a 1D sequence of length 4096.
Adding positional info: Since flattening removes explicit (x, y) structure, positional encodings are added so the model can recover spatial relationships.
Stacking S4D layers: Stacks four S4D blocks, each operating over (batch size = 8, feature dimensions from step 1, sequence length = 4096). Residual connections are used between layers to stabilize optimization and improve gradient flow. Mimicking the CNN-VAE baseline, a dropout layer is applied (0.1), meaning each feature has a 10% chance of being zeroed during training.
Mean pooling across positions: Averages over all 4096 sequence positions to produce a single feature vector per image.
Predict μ and log 𝜎2: Uses the pooled representation to output the parameters of the approximate posterior.
Creating a VAE with SSM layers instead of CNNs was significantly harder than I expected. I initially assumed that the swap would be solely architectural, keeping the encoder and decoder function from VAE with CNNs intact. In practice, though, training has additional constraints—such as GPU memory limits that forced the batch size to drop from 32 to 8 images. This significantly increased the required time from training, making it last ~10 hours for 200,000 steps.
5. Human Comparison Evaluations:
While benchmarks are helpful from a quantitative perspective, they often don’t yield insightful results for better understanding how humans actually feel about models. So, I also asked 12 of my friends from the Claremont Colleges (7 at Claremont McKenna, 2 at Harvey Mudd, 2 at Pomona, 1 at Pitzer) to evaluate the images on a scale of 1-10 for realism. Each participant was presented with the two images (Figure 1 and Figure 3, as visualized in Results below), and verbally asked the simple question: “if you had to rate each of these images on a scale of 1-10 for realism, what would you assign them?” Results are displayed below in 4.3 (Results).
Results
1. CNN-only results:
While the faces that my model generated were not as beautiful as the celebrities in the initial dataset, the VAE model certainly generated images with strong resemblance of faces, as illustrated below.

Three standard training loss evaluation metrics for VAEs are Negative Evidence Lower Bound (NELBO), Reconstruction Loss (REC), and Kullback-Leibler Divergence (KL). NELBO is best-suited for assessing overall model performance; REC is great for assessing the extent to which the model can reconstruct its input data; KL is great for measuring the proximity of learned latent distribution to the prior distribution.
Attached below are the training curves for the VAE model, showing the progression of the NELBO, REC, and KL metrics over the 200,000 training steps.

If I allocated more time, I’d also use image generation-specific evaluation criteria to assist with quantitatively comparing the two models.
2. SSM-VAE hybrid results:

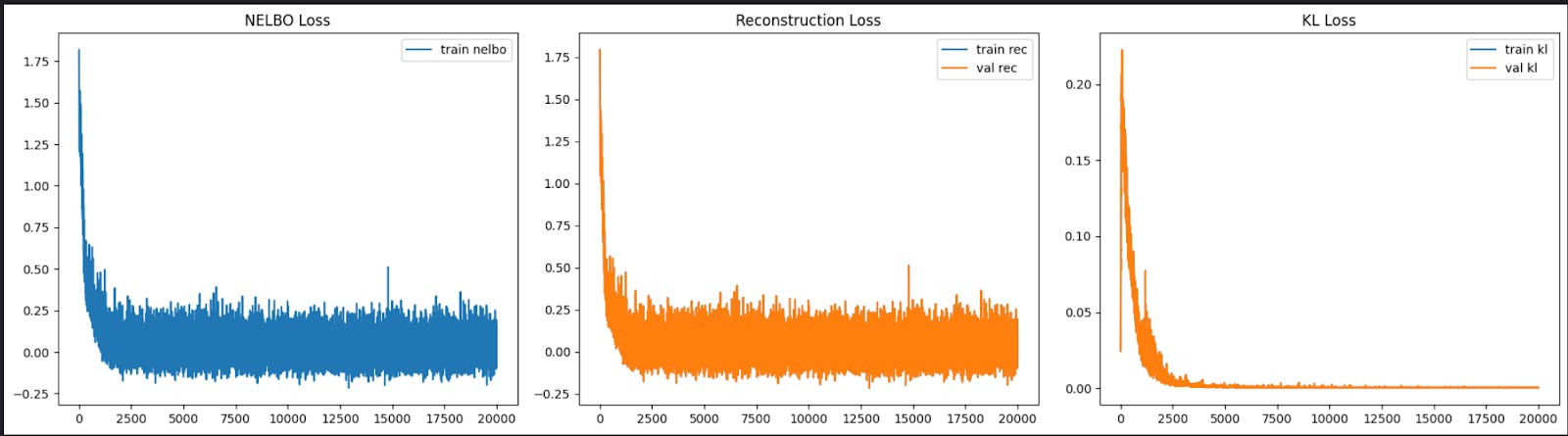
The total NELBO loss drops from 1.8 to 0.2 in the first 2,000 steps. Similarly, the reconstruction loss also crashes down to 0.1 in the first 2,000 steps. For both losses, the losses hover at that level for the rest of training. The KL loss starts at 0.2 but falls to 0 by 2,000 steps and stays there. This suggests that the model is overfitting, which is visible from the generated sample images.
3. Comparing the Models:
To compare, these were the final loss ranges for each of the two models:

And, these were the scores given by the 12 Claremont College students for their perceived realism of the two sets of images:
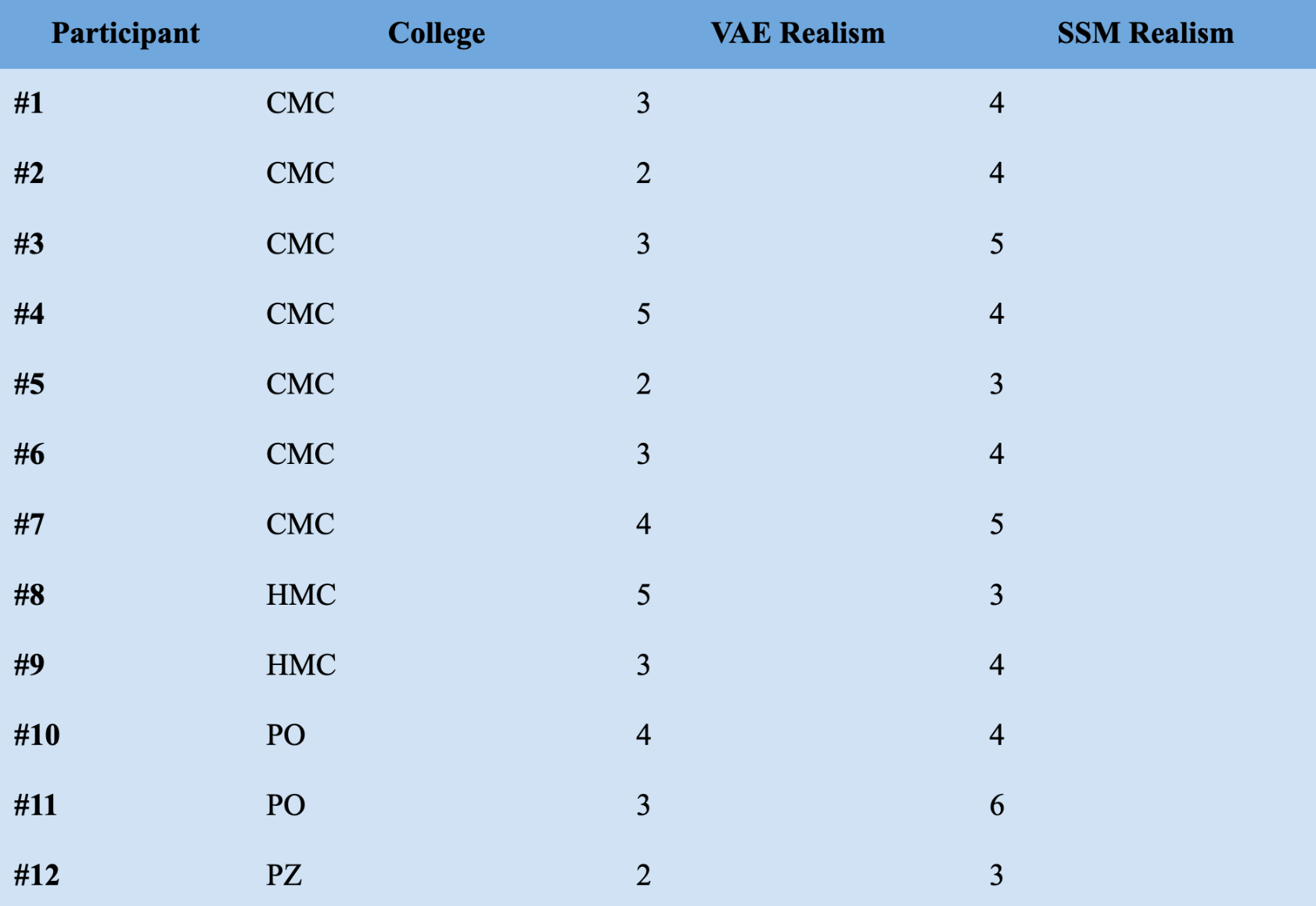
The breakdown by college is as follows:
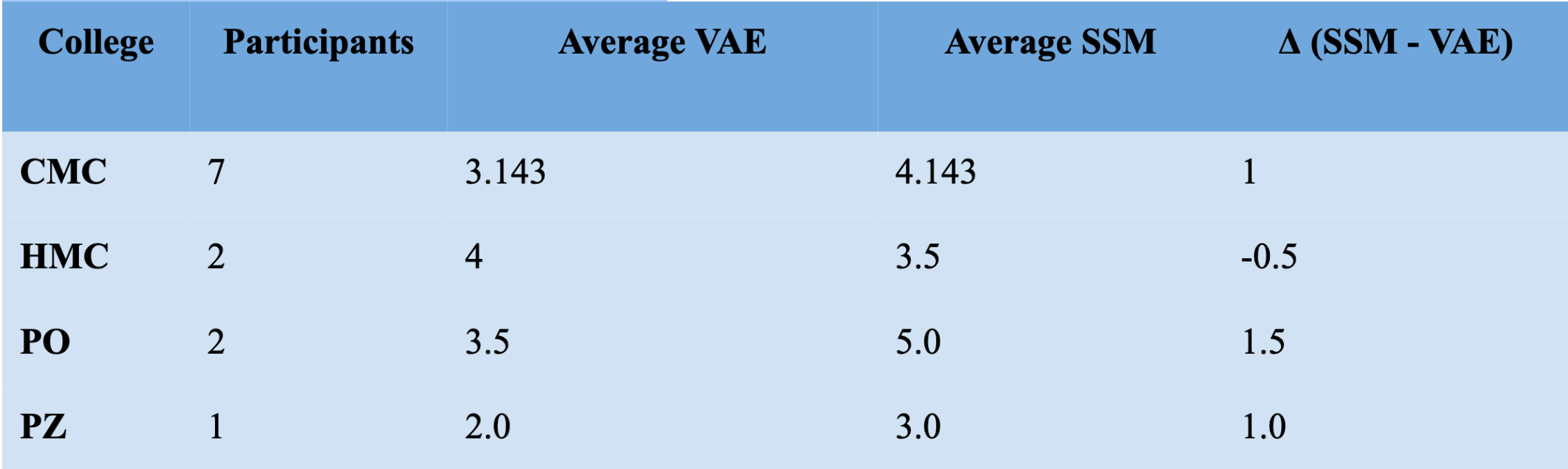
In total, the average VEA realism score was 3.25, the average VAE+SSM realism score was 4.08, and the average improvement score (SSM - VAE) was 0.83. Only 2 participants ranked the VAE as seemingly more real than the VAE+SSM, while 9 participants ranked the VAE+SSM as more real and 1 person had a tie.
Analysis
Overall, from the qualitative analysis, it can be observed that participants preferred the SSM generated images over the CNN generated images! This is a promising signal that SSMs for image generation may be interesting to further investigate. However, looking at the images more closely highlights that none of them host much uniqueness, as the faces all look quite similar and the KL loss dropped significantly.
The sudden drop in KL loss suggests that the SSM-based VAE model experienced posterior collapse—which occurs when the approximate posterior matches the prior one such that the latent variables carry little-to-no information (effectively reverting to the same Normal prior). A likely reason for this is that the KL weight ramped up too quickly, preventing the model from learning a useful latent representation and encouraging a degenerate solution that optimizes the objective. As a result, the model learns to reproduce an “average” output rather than generating diverse synthetic samples, as shown in the figure below.

A new VAE technique that is worth exploring in the future is neural discrete representation learning since it prevents posterior collapse [14]. Comparing the negative ELBO loss between both models, the CNN-based VAE is down to between -1.27 to -1.24 after 20,000 steps whereas the SSM based VAE is down to between -0.25 and 0.25. The more negative the value, the better the pixels are being modeled, hence the CNN based VAE did better in this metric. Overall, I believe SSMs are likely to be well-equipped for 1D sequential data (like audio), but for static images the flattened sequence representation can obscure 2D spatial structure and limit reconstruction fidelity.
Future directions of further exploration could include substituting layers for updated versions of VAEs such as Vector Quantised-Variational AutoEncoder [14], diffusion models, other architectures with SSM layers, or a fully SSM-based approach; using the annotations of CelebA to create synthetic images of humans with different attributes (e.g., age, gender); training on datasets other than CelebA; using other image generation evaluation metrics (e.g., Inception Score, Fréchet Inception Distance, Structural Similarity Index Measure); training with different batch sizes or for different amounts of steps; doing more human testing for subjective opinions; and applying all these methods for video generation!
References
[1] A. Gu, K. Goel, and C. Ré. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396, 2021.
[2] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial networks. arXiv preprint arXiv:1406.2661, 2014.
[3] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein GAN. arXiv preprint arXiv:1701.07875, 2017.
[4] J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. arXiv preprint arXiv:2006.11239, 2020.
[5] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. arXiv preprint arXiv:2112.10752, 2021.
[6] A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023.
[7] E. Nguyen, K. Goel, A. Gu, G. W. Downs, P. Shah, T. Dao, S. A. Baccus, and C. Ré. S4ND: Modeling images and videos as multidimensional signals using state spaces. arXiv preprint arXiv:2210.06583, 2022.
[8] Y. Hong, L. Mai, Y. Yao, and F. Liu. Pushing the boundaries of state space models for image and video generation. arXiv preprint arXiv:2502.00972, 2024.
[9] Y. Liu, Y. Tian, Y. Zhao, H. Yu, L. Xie, Y. Wang, Q. Ye, and Y. Liu. VMamba: Visual state space model. arXiv preprint arXiv:2401.10166, 2024.
[10] A. Mondal, S. Alletto, and D. Tome. HumMUSS: Human motion understanding using state space models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
[11] C. Kang. VAE for the CelebA dataset. Blog post, 2021. Available: https://goodboychan.github.io/python/coursera/tensorflow_probability/icl/2021/09/14/03-Variational-AutoEncoder-Celeb-A.html. Accessed: 2024-05-16.
[12] J. Gentić. VAE_celeba. GitHub repository. Available: https://github.com/Jovana-Gentic/VAE_celeba. Accessed: 2024-05-16.
[13] J. Gentić. pytorch VAE: celeba. Kaggle notebook. Available: https://www.kaggle.com/code/jovanagenti/pytorch-vae-celeba. Accessed: 2024-05-16.
[14] A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural Discrete Representation Learning,” arXiv preprint arXiv:1711.00937, 2017. [Online]. Available: https://arxiv.org/abs/1711.00937
Regarding the topic of the article, the focus on addressing Transformer bottlenecks with SSMs is incredibly important for the future of AI scalabilty. I wonder how solving these compute and memory issues might change what kind of AI applications become mainstream and accesible outside of current frontier labs?